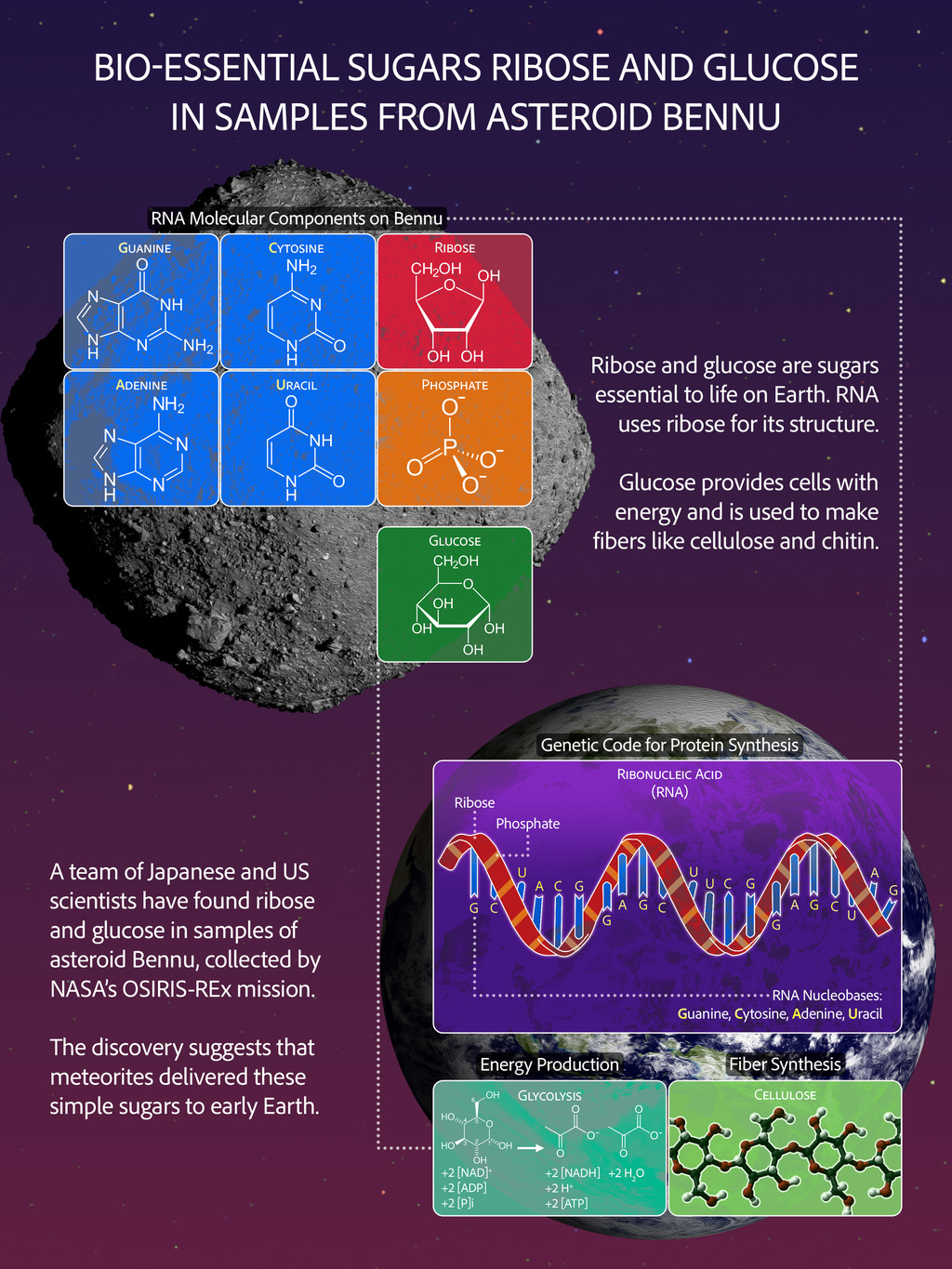
مارک همیلتون، دانشجوی دکترای MIT، با مشاهده صحنهای از این فیلم که یک پنگوئن هنگام بلند شدن نالهای از سر ناراحتی سر میدهد، به این فکر افتاد که آیا میتوان به یک الگوریتم اجازه داد با تماشای تلویزیون، زبان انسان را بیاموزد. DenseAV با پیشبینی آنچه میبیند از آنچه میشنود و بالعکس عمل میکند. بهعنوان مثال، اگر صدای کسی را بشنود که میگوید "کیک را در دمای 350 درجه بپزید"، احتمالاً بهدنبال کیک یا فر در تصویر میگردد.
الگوریتم جدیدی به نام DenseAV در دانشگاه MIT توسعه
یافته است که با تماشای ویدئوهای افراد در حال گفتگو، زبان را تجزیه و تحلیل کرده
و معنای آن را درک میکند. این الگوریتم با تطبیق صدا و تصویر در میلیونها ویدئو،
یاد میگیرد که افراد در مورد چه چیزی صحبت میکنند و کاربردهای بالقوهای در
جستجوی چندرسانهای، یادگیری زبان و رباتیک دارد. ایده اولیه این الگوریتم از فیلم
"رژه پنگوئنها" الهام گرفته شدهاست. مارک
همیلتون، دانشجوی دکترای
MIT، با
مشاهده صحنهای از این فیلم که یک پنگوئن هنگام بلند شدن نالهای از سر ناراحتی سر
میدهد، به این فکر افتاد که آیا میتوان به یک الگوریتم اجازه داد با تماشای
تلویزیون، زبان انسان را بیاموزد. DenseAV با پیشبینی آنچه میبیند از
آنچه میشنود و بالعکس عمل میکند. بهعنوان
مثال، اگر صدای کسی را بشنود که میگوید "کیک را در دمای 350 درجه
بپزید"، احتمالاً بهدنبال کیک یا فر در تصویر میگردد. پس از
آموزش، محققان بررسی کردند که وقتی مدل صدایی را میشنود، بهدنبال
کدام پیکسلها میگردد.
بهعنوان
مثال، وقتی کسی میگوید "سگ"، الگوریتم بلافاصله شروع به جستجوی سگها
در ویدئو میکند. با مشاهده اینکه کدام پیکسلها توسط الگوریتم انتخاب میشوند، میتوان
کشف کرد که الگوریتم چه معنایی برای یک کلمه در نظر میگیرد. جالب اینجاست که وقتی DenseAV صدای پارس سگ را میشنود، فرآیند جستجوی مشابهی
برای یافتن سگ در ویدئو آغاز میشود. این موضوع باعث شد تیم تحقیقاتی به این فکر
بیفتد که آیا الگوریتم میتواند بین کلمه "سگ" و صدای پارس سگ تمایز
قائل شود یا خیر. با افزودن یک "مغز دوطرفه" به DenseAV،
آنها دریافتند که یک طرف مغز بهطور طبیعی بر روی زبان (مانند کلمه
"سگ") و طرف دیگر بر روی صداها (مانند پارس) تمرکز میکند. این نشانمیدهد که
DenseAV نهتنها معنای کلمات و مکان صداها را یاد گرفته، بلکه میتواند بین این
انواع ارتباطات متقاطع تمایز قائل شود، بدون دخالت انسان یا دانش قبلی از زبان
نوشتاری.
این الگوریتم کاربردهای
بالقوه زیادی دارد، از جمله یادگیری از حجم عظیم ویدئوهای آموزشی در اینترنت، درک
زبانهای جدید بدون شکل نوشتاری (مانند ارتباط دلفینها و نهنگها)، و حتی کشف
الگوها بین سایر جفت سیگنالها (مانند صداهای لرزهای و زمینشناسی). چالش اصلی
تیم، یادگیری زبان بدون هیچ ورودی متنی بود. هدف آنها کشف مجدد معنای زبان از
ابتدا بود، بدون استفاده از مدلهای زبانی از پیش آموزشدیده.
این رویکرد از نحوه یادگیری کودکان با مشاهده و گوش دادن به محیط اطرافشان الهام
گرفته شدهاست. DenseAV از دو جزء اصلی برای پردازش جداگانه دادههای صوتی و تصویری استفاده میکند.
این جداسازی باعث میشود الگوریتم نتواند تقلب کند و مجبور شود اشیا را تشخیص داده
و ویژگیهای دقیق و معنیدار برای سیگنالهای صوتی و تصویری ایجاد کند. DenseAV با مقایسه جفت سیگنالهای صوتی و تصویری، یاد میگیرد
که کدام سیگنالها با هم مطابقت دارند و کدام سیگنالها با هم مطابقت ندارند. این
روش، که یادگیری متضاد نامیده میشود، نیازی به نمونههای برچسبگذاری شده ندارد و
به
DenseAV اجازه میدهد تا
الگوهای پیشبینی مهم زبان را بهتنهایی کشف کند.
یک تفاوت عمده DenseAV با الگوریتمهای قبلی در این است که بهجای تطبیق یک کلیپ صوتی کامل با کل تصویر، تمام تطابقهای ممکن بین یک
کلیپ صوتی و پیکسلهای یک تصویر را جستجو و تجمیع میکند. این کار باعث بهبود
عملکرد و امکان مکانیابی دقیقتر صداها میشود. در روشهای قبلی، یک کلیپ صوتی
مانند "سگ روی چمن نشست" با کل تصویر یک سگ مطابقت داده میشد، اما DenseAV میتواند ارتباط بین کلمه "چمن" و چمن
زیر سگ را نیز تشخیص دهد. محققان
DenseAV را با استفاده از AudioSet، شامل 2 میلیون ویدئوی یوتیوب، آموزش دادند و یک مجموعه داده جدید
با حاشیهنویسیهای دقیق پیکسلی برای ارزیابی عملکرد مدل ایجاد کردند. در آزمایشها،
DenseAV در کارهایی مانند شناسایی اشیا از نام و صداهایشان، از سایر مدلهای برتر عملکرد بهتری داشت. تکمیل این پروژه حدود یک
سال طول کشید و چالشهایی مانند انتقال به یک معماری ترانسفورماتور بزرگ و تشویق
مدل به تمرکز بر روی جزئیات دقیق را بههمراه داشت. در
آینده، تیم قصد دارد سیستمهایی ایجاد کند که بتوانند از مقادیر عظیم دادههای فقط
ویدیوئی یا فقط صوتی یاد بگیرند و این روش را با استفاده از ستون فقرات بزرگتر
مقیاسبندی کنند. همچنین، آنها احتمالاً دانش را از مدلهای زبانی ادغام میکنند
تا عملکرد را بهبود بخشند.
دیوید هاروَث، استادیار علوم
کامپیوتر در دانشگاه تگزاس در آستین، که در این تحقیق شرکت نداشتهاست، بر اهمیت
DenseAV تأکید میکند. او میگوید
که تشخیص اشیا بصری در تصاویر و صداهای محیطی و کلمات گفتاری در ضبطهای صوتی، هر
کدام بهتنهایی چالشهای دشواری هستند. در گذشته،
محققان برای آموزش مدلهای یادگیری ماشین برای انجام این وظایف به حاشیهنویسیهای
گرانقیمت و انسانی نیاز داشتند. اما
DenseAV با مشاهده ساده جهان
از طریق بینایی و صدا، این وظایف را بهطور همزمان حل میکند.
این مدل همچنین هیچ فرضی در مورد زبان خاصی که صحبت میشود ندارد و میتواند از
دادهها به هر زبانی یاد بگیرد. هاروَث ابراز هیجان میکند که ببیند DenseAV با مقیاسبندی به هزاران یا میلیونها ساعت دادههای
ویدیوئی در زبانهای مختلف، چه چیزهایی میتواند یاد بگیرد. نویسندگان دیگری که در
این مقاله مشارکت داشتهاند عبارتند از اندرو زیسرمن، استاد مهندسی بینایی
کامپیوتر در دانشگاه آکسفورد، جان آر. هرشی، محقق ادراک هوش مصنوعی گوگل، و ویلیام
تی. فریمن، استاد مهندسی برق و علوم کامپیوتر MIT و محقق
اصلی CSAIL. این تحقیق با حمایت مالی بنیاد ملی علوم
ایالات متحده، یک استاد پژوهشی انجمن سلطنتی، و یک کمک هزینه برنامه EPSRC Visual AI انجام شدهاست و در کنفرانس
بینایی کامپیوتر و تشخیص الگو
IEEE/CVF در این ماه ارائه
خواهد شد.